LLM Deepseek相关
最后更新时间:
基本原理
- token 一个词语或者词组,--(embedding) --->对应一个向量,表示含义
- 每次根据前文预测下一个词语
- Attention层+多层感知层+Attention层+.....
- Attention层:pass information around the token into its vector
- 查询矩阵 * 嵌入向量 -> 查询向量 (like looking for adj of it,降维)
- 键向量,回答查询 (降维)
- 每个查询向量和键向量的相似度( \(n^2\),n为上下文长度 ) -> the embeddings of x attend to the embedding of y
- 值矩阵 * 嵌入向量:值向量 (shape与嵌入向量相同)
- 值向量用相关性为权重进行加权相加 (每个位置只被此位置前面的token影响:掩码)-> \(\Delta E\)
- 值参数矩阵太大 -> 变成两个参数矩阵相乘 (\(V_{up} * V_{down} (* E)\))
- 单头和多头 不同的注意力模式(W,K,V参数矩阵不一样)-> 所有 \(\Delta E\) 相加
- V_up 合起来为输出矩阵
- 自注意力和交叉注意力
- 多层感知层:每个token单独处理,存储事实
- \(W_{up} \times E + B_{up}\)
(注意升维了)
- ReLU函数激活(得到的值叫做神经元)
- \(W_{down} \times E + B_{down}\) (注意降维了)
- 事实存储在wup的行向量(像embedding一样代表一种特征)和对应的wdown的列向量的关系中
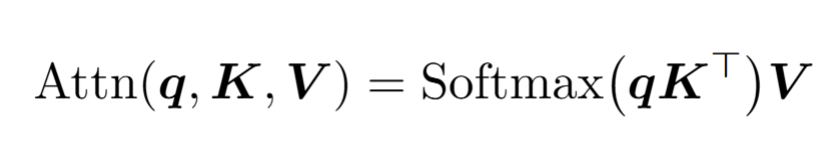
- \(W_{up} \times E + B_{up}\)
(注意升维了)
![]()
 ##
Deepseek原理 - MLE多头潜在注意力 = 多头自注意力+低秩联合压缩 - MoE
每个token激活8个专家,共享专家+路由专家 -
辅助损失的主要作用 是在训练过程中鼓励 token
更均匀地分配给不同的专家。无辅助损失的负载均衡策略:采用
动态偏置项(Bias Term)
来调整专家的选择概率。监控每个专家的负载来调整概率。 - MTP
同时预测多个后续token - train: - PP:流水线 -> DualPipe -
EP:专家并行 - DP:数据并行 - 大多数核心计算内核,即 GEMM(General
Matrix Multiply)操作,以 FP8 精度实现。保持以下组件的原始精度(例如
BF16 或 FP32):嵌入模块、输出头、MoE
门控模块、归一化操作符和注意力操作符。 - Adam
它是一种自动调整学习率的算法,优化器 - Wgrad
操作(权重反向传播,Weight Gradient) - 通信带宽是 MoE
模型训练的关键瓶颈。 ### 部署 -
“部署”指的是将训练好的模型应用到实际场景中的过程,使其能够在特定环境中运行并提供服务
-
MoE的全对全通信:跨节点通信使用高速网络(如InfiniBand,IB);节点内通信在节点内部,通过GPU之间的NVLink
-
预填充和解码:推理的两个阶段,预填充是用prompt生成第一个输出token,解码是一个一个输出token。预填充阶段计算密集,适合高性能计算资源;解码阶段计算稀疏,适合低延迟优化
- KV
Cache:在自回归生成任务中,模型每次生成一个新token时,都需要计算当前token与之前所有token之间的注意力关系。KV
Cache 通过缓存之前计算过的K和V矩阵,避免重复计算,从而显著提高推理效率。
## 通道
在图像处理或卷积神经网络(CNN)中,“通道”通常指特征图的一个维度,直接对应某个卷积核的输出。但在Transformer中,“通道”并不是一个原生术语,而是可以借用过来描述多头注意力输出的结构:
- 隐式通道:拼接后的输出向量(例如 512 512 512
维)可以被看作包含 h h h 个“通道”,每个通道的长度是 dhead d_{head}
dhead(例如 64 64 64)。这里的“通道”实际上是每个注意力头的输出片段。 -
特征表示:每个“通道”(即每个头的输出)捕获输入数据的不同方面,例如语法、语义、上下文关系等。
##
Deepseek原理 - MLE多头潜在注意力 = 多头自注意力+低秩联合压缩 - MoE
每个token激活8个专家,共享专家+路由专家 -
辅助损失的主要作用 是在训练过程中鼓励 token
更均匀地分配给不同的专家。无辅助损失的负载均衡策略:采用
动态偏置项(Bias Term)
来调整专家的选择概率。监控每个专家的负载来调整概率。 - MTP
同时预测多个后续token - train: - PP:流水线 -> DualPipe -
EP:专家并行 - DP:数据并行 - 大多数核心计算内核,即 GEMM(General
Matrix Multiply)操作,以 FP8 精度实现。保持以下组件的原始精度(例如
BF16 或 FP32):嵌入模块、输出头、MoE
门控模块、归一化操作符和注意力操作符。 - Adam
它是一种自动调整学习率的算法,优化器 - Wgrad
操作(权重反向传播,Weight Gradient) - 通信带宽是 MoE
模型训练的关键瓶颈。 ### 部署 -
“部署”指的是将训练好的模型应用到实际场景中的过程,使其能够在特定环境中运行并提供服务
-
MoE的全对全通信:跨节点通信使用高速网络(如InfiniBand,IB);节点内通信在节点内部,通过GPU之间的NVLink
-
预填充和解码:推理的两个阶段,预填充是用prompt生成第一个输出token,解码是一个一个输出token。预填充阶段计算密集,适合高性能计算资源;解码阶段计算稀疏,适合低延迟优化
- KV
Cache:在自回归生成任务中,模型每次生成一个新token时,都需要计算当前token与之前所有token之间的注意力关系。KV
Cache 通过缓存之前计算过的K和V矩阵,避免重复计算,从而显著提高推理效率。
## 通道
在图像处理或卷积神经网络(CNN)中,“通道”通常指特征图的一个维度,直接对应某个卷积核的输出。但在Transformer中,“通道”并不是一个原生术语,而是可以借用过来描述多头注意力输出的结构:
- 隐式通道:拼接后的输出向量(例如 512 512 512
维)可以被看作包含 h h h 个“通道”,每个通道的长度是 dhead d_{head}
dhead(例如 64 64 64)。这里的“通道”实际上是每个注意力头的输出片段。 -
特征表示:每个“通道”(即每个头的输出)捕获输入数据的不同方面,例如语法、语义、上下文关系等。
因此,在这种意义上,可以说“一个通道对应一个注意力头的输出”。但需要注意:
-
这些“通道”在拼接后会被线性变换(通过一个全连接层),最终输出不再保留明确的“通道”边界,而是融合成了一个统一的
dmodel d_{model} dmodel 维向量。 -
“通道”在这里更多是一个概念上的类比,而不是像CNN中那样有明确的物理分离。
低秩分解
在多头注意力机制(MHA)中,键(K)和值(V)矩阵通常需要占用大量内存。通过低秩分解,可以将K和V矩阵压缩为一个低秩的潜在表示(如 ),从而减少存储需求。