组原
最后更新时间:
注意补码的移位和扩展都是符号扩展 ## 数电 - 最小项 A是最高位 - ieee754
1 8 23 ;1 11 52 ## 编码 - 为保持与十进制数的唯一对应,
2421码不使用0101~ 1010等6种状态。
5不是0101而是1011开始。对9的自补,按位取反=9-x。 -
余三:无权码(8421,2421是有权),对9自补(按位取反=15-(x+3)=(9-x)+3 -
格雷:格雷码任意两个相邻数仅有一位不同 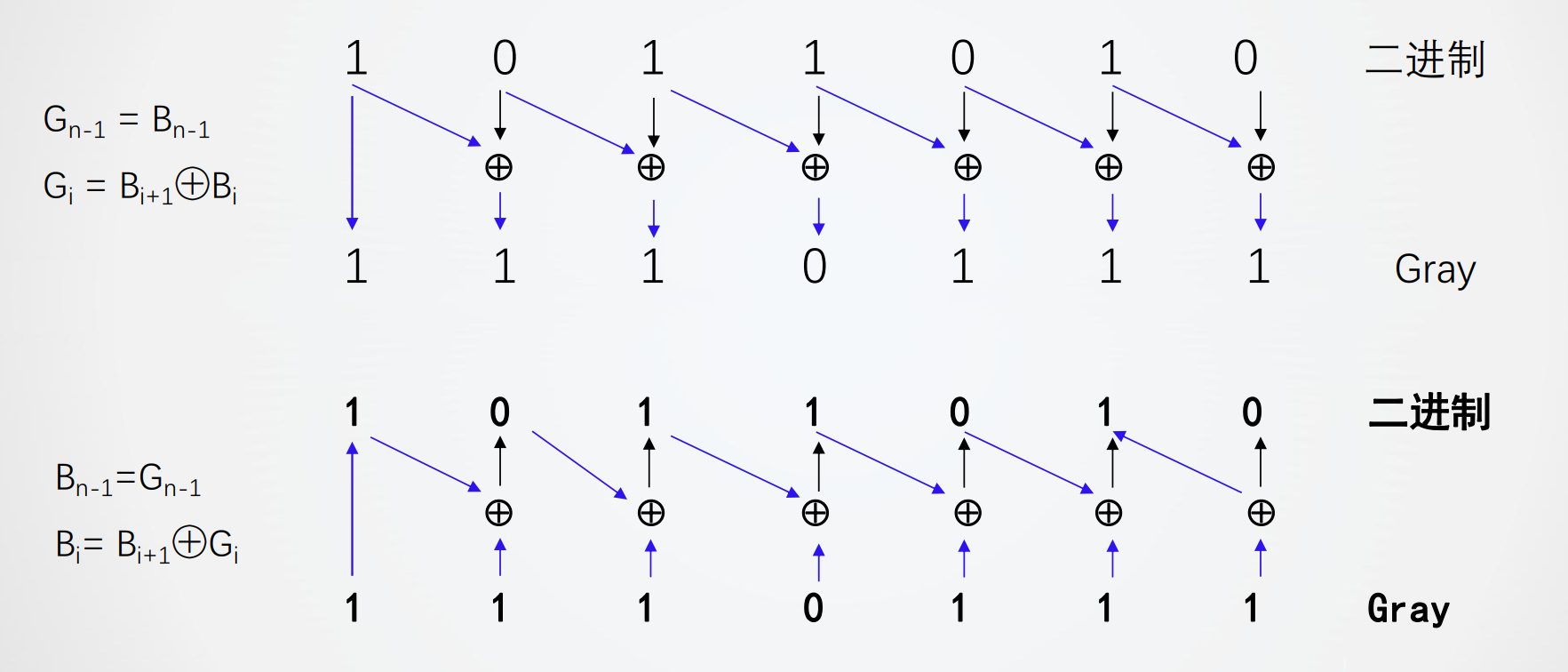 - 码距:
同一编码体系中,任意两个合法编码(value)之间二进制数(key)不同位数的最小值。校验码中增加冗余项的目的就是为了扩大码距
- 检错和纠错:
- 码距:
同一编码体系中,任意两个合法编码(value)之间二进制数(key)不同位数的最小值。校验码中增加冗余项的目的就是为了扩大码距
- 检错和纠错: d-1 and (d-1)//2 -
奇偶校验:最后一位看前面1个数的奇偶,只能验错,2位 - ## 运算器 -
多路分配器就是多路选择器反过来 - 加法器 - 串行:行波进位加法器:\(S_t = X_t \oplus Y_t \oplus C_t\) \(C_{t+1} = X_t Y_t + (X_t \oplus Y_t) C_t\)
- 可控加减法:y^=ifsub c0=ifsub - 溢出 Cn ^ Cn+1 ,
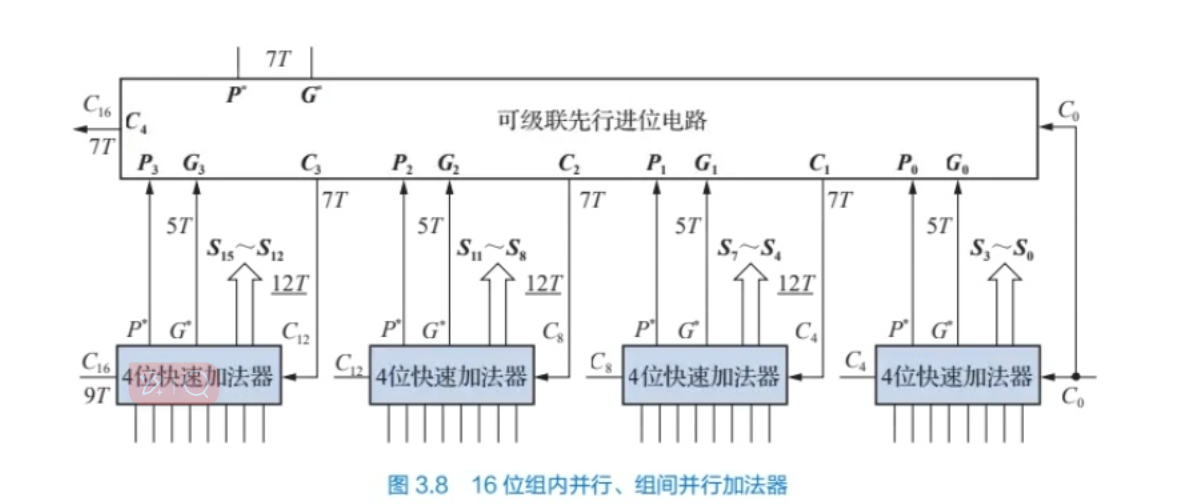
Cn+1是符号位运算后的溢出 - 并行:先行进位加法器 -
d-1 and (d-1)//2 -
奇偶校验:最后一位看前面1个数的奇偶,只能验错,2位 - ## 运算器 -
多路分配器就是多路选择器反过来 - 加法器 - 串行:行波进位加法器:\(S_t = X_t \oplus Y_t \oplus C_t\) \(C_{t+1} = X_t Y_t + (X_t \oplus Y_t) C_t\)
- 可控加减法:y^=ifsub c0=ifsub - 溢出 Cn ^ Cn+1 ,
Cn+1是符号位运算后的溢出 - 并行:先行进位加法器 -  - Ci+1 = Gi+PiCi
-> Ci = f(G, P, C0) - Ci+4 = G*i+P*iCi -> Ci*4 = f(G, P,
C0)
- Ci+1 = Gi+PiCi
-> Ci = f(G, P, C0) - Ci+4 = G*i+P*iCi -> Ci*4 = f(G, P,
C0)
-  - 乘法器 -
原码一位乘法:类似快速幂 1. if (y0 == 1) p+=x; else p+=0; 2. (c_out + p
+ y)>>=1 => reg , i++ until i == n
(移位的时候答案p0变成y的高位,n次做完之后移位之后放入寄存器的就是答案 -
补码一位乘法:
- 乘法器 -
原码一位乘法:类似快速幂 1. if (y0 == 1) p+=x; else p+=0; 2. (c_out + p
+ y)>>=1 => reg , i++ until i == n
(移位的时候答案p0变成y的高位,n次做完之后移位之后放入寄存器的就是答案 -
补码一位乘法: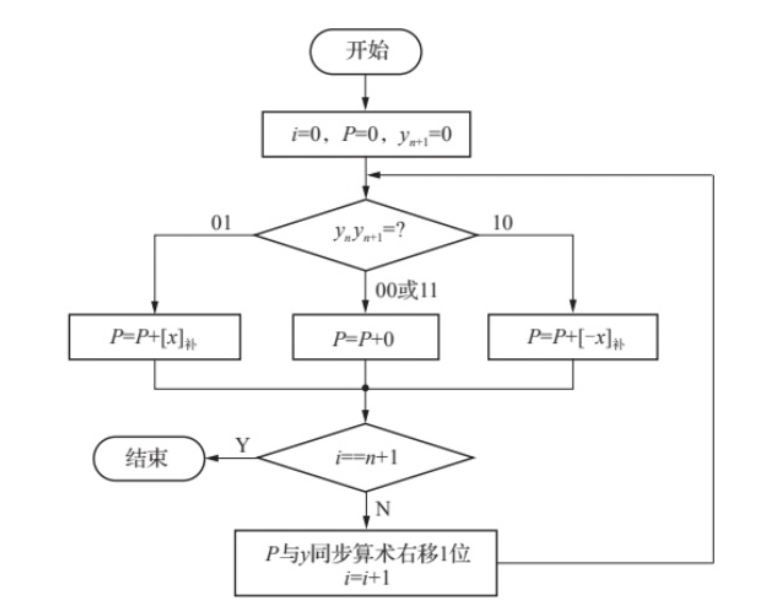 -
阵列乘法器
-
阵列乘法器 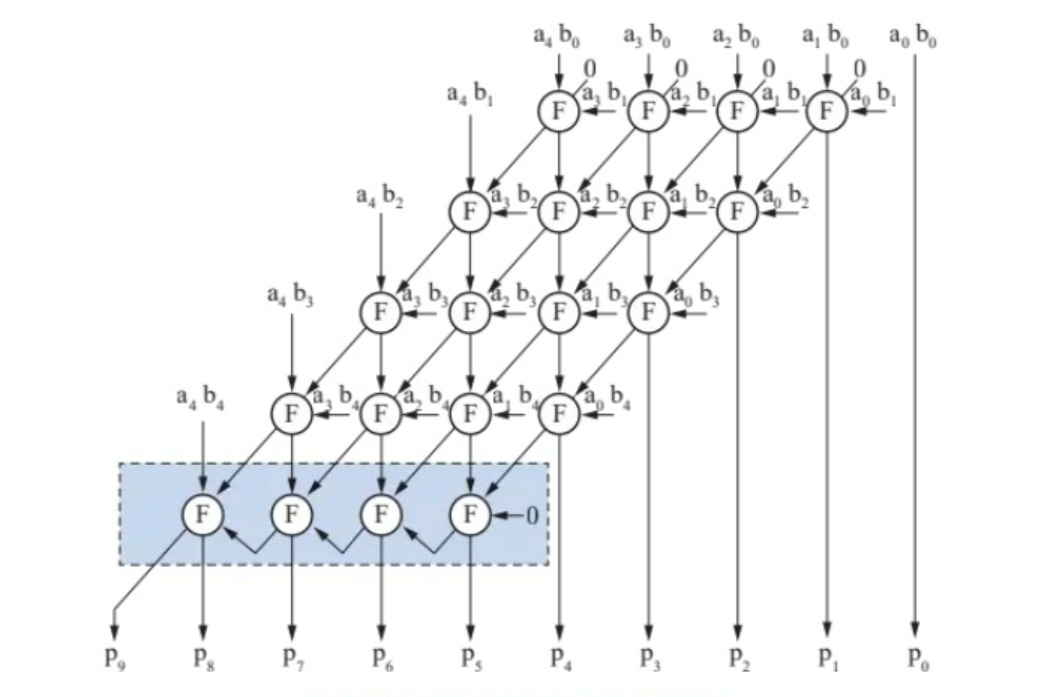 -
一行内的进位不与此行更高位关联,而是和下一行的更高位,从而做到并行 o(n)
- 除法器 - 原码不恢复余数法:\(R_{i+1} =
2R_i+(-1)^{q_i = seg(R_i)}y\) 1. Ri +=(-1)^q0 * y 2. q =
q<<1+(Ri > 0) 3. Ri <<=1 - 阵列除法器 (O(n^2)) -
-
一行内的进位不与此行更高位关联,而是和下一行的更高位,从而做到并行 o(n)
- 除法器 - 原码不恢复余数法:\(R_{i+1} =
2R_i+(-1)^{q_i = seg(R_i)}y\) 1. Ri +=(-1)^q0 * y 2. q =
q<<1+(Ri > 0) 3. Ri <<=1 - 阵列除法器 (O(n^2)) - 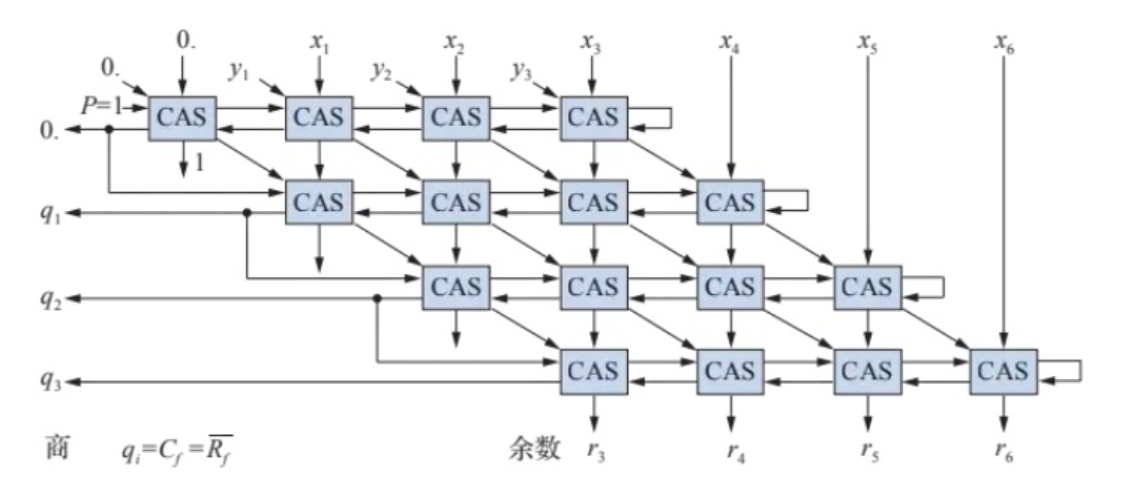 (其中CAS是可控加减法单元,斜着不变是y)
## 同步时序电路 特征方程
(其中CAS是可控加减法单元,斜着不变是y)
## 同步时序电路 特征方程  钟控:只有ck为1的时候随便变 ## 存储器
钟控:只有ck为1的时候随便变 ## 存储器
SRAM,DRAM,ROM
题 1、某动态存储器存储单体的容量是\(64K*8\)位,采用双译码结构且地址线平均送到两个译码器,刷新周期是2ms (abc) A.动态存储器的刷新按行进行 B.该动态存储器的刷新地址计数器的模为2^8 C.该动态存储单体地址线之和为16
2、下列属于导致DRAM 比SRAM慢的原因是abc A.DRAM需要刷新操作 B.DRAM 读写过程中其地址分行、列分时传送,行列地址线复用 C.读操作前先要进行预充操作 D.DRAM的容量比SRAM容量大
集中刷新虽然保持了存储单体的高速特性,但存在死时间 00001111 异步刷新方式既保持了存储单体的高速特性,也不存在死时间 00001000001 分散刷新由于刷新次数过多,大大降低了存储单体的性能 010101
读操作也具有刷新功能 某DRAM芯片地址引脚数据为12根,则其容量为16M
掩模ROM(MROM)是只读存储器,由厂家写入固定程序,用户无法修改;PROM可由用户编程一次,写入后不可改写;EPROM可通过紫外线擦除并重新编程;EEPROM支持电擦除和重写,适合频繁更新数据;Flash Memory则是一种非易失性存储器,支持快速擦写,广泛用于存储卡和U盘等设备。
位/字扩展
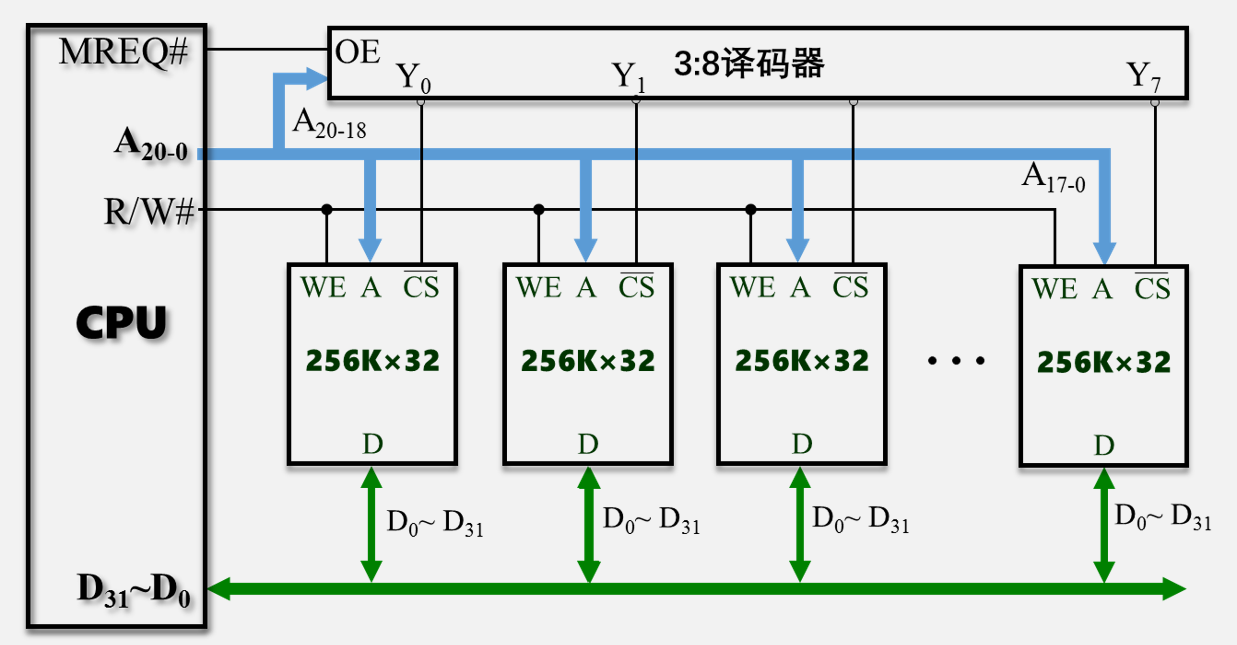
位扩展 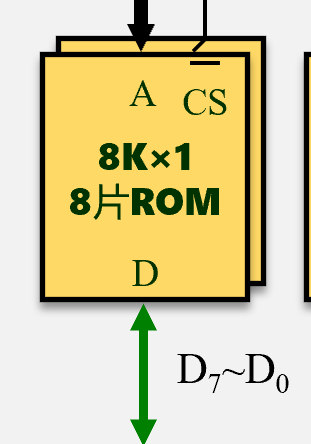 #
或者上面横线表示:低电平有效 WE write enable (ROM没有) MREQ memory
request CS chip select 片选(选哪一片) R/W 高写 (R/W#为低电平(写))
A D A高3位给mux,D平分 先看要多少片,再看扩展方向
#
或者上面横线表示:低电平有效 WE write enable (ROM没有) MREQ memory
request CS chip select 片选(选哪一片) R/W 高写 (R/W#为低电平(写))
A D A高3位给mux,D平分 先看要多少片,再看扩展方向
主存
主存一般按字节编址 -> xxx*8位(地址范围*存储单元)
cache
- 时间局部性和空间局部性
for(int i = 1; i <= 100;i++) sum+=a[i]i,sum 时间,a空间 - 命中率,缺失率,访问效率 (命中访问时间 / 平均访问时间)(最理想就是都命中:1)
- 写穿(每次写都会写到主存) and 写回
- 写分配法:要写的块未命中,则先从主存弄到cache。否则直接写到主存里
- 块包含若干个字,是cache和主存直接传递信息的单位
- 映射
- 全相联映射
- address = tag + offset
- tag作为key,用相联存储器(CAM,查找表,并发比较)
- 直接相联映射
- address = tag + index + offset
- index是行号,所有行号相同的地址都会存储在一个地方(冲突)(相当于hash),index的范围就是cache的行数
- 组相联映射
- 前两者折中
- 先直接相联,但是每个组号(上面的行号)相同的会对于一个CAM(k行->k路)
- 全相联映射
- cache的总容量 = n * (有效位+tag+块大小) 注意B和bit转换 ###
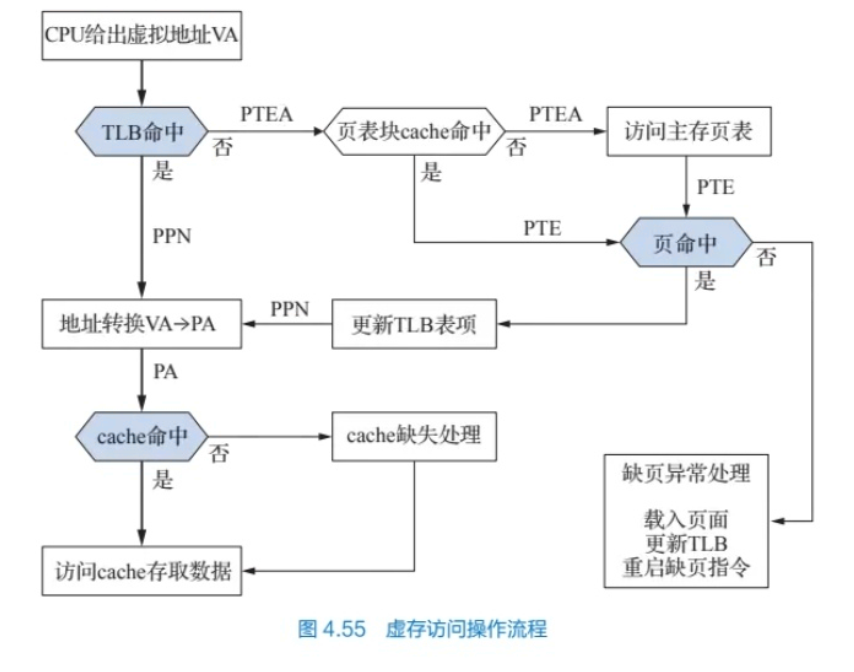
虚拟存储器 MMU:通过虚拟地址找到物理地址的硬件
TLB:页表的cache(把vpn分为tag+offset) PTE:页表
PTEA:页表地址=base+虚拟页号 PPN:物理页号 物理地址PA=物理页号+页偏移
01C60H 中的H是十六进制的意思
指令系统
寻址方式
指令寻址 - 顺序寻址 - 跳转寻址 操作数寻址 + 立即寻址 +
地址码字段是操作数本身(相当于不用寻址,直接就是操作数) + 直接寻址 +
间接寻址 + 需要两次访存,速度慢,已经淘汰 + 寄存器寻址 + 寄存器间接寻址 +
相对寻址 PC+X + 基址/变址寻址 ,
MOV DX, D[EBP] (E = (EBP)*16 +D)
(区别是概念上的,基址+偏移量(哪个是寄存器)) + 复合寻址
注意问的是数据还是地址
操作码扩展
操作码字段不固定 双操作数操作码k位,有m条,则有 \((2^k - m) * 2^t\) 可以单,t是单操作数多出来的
相对寻址,注意pc+=当前指令字节数 1byte=8bit ## cpu ### 指令类型
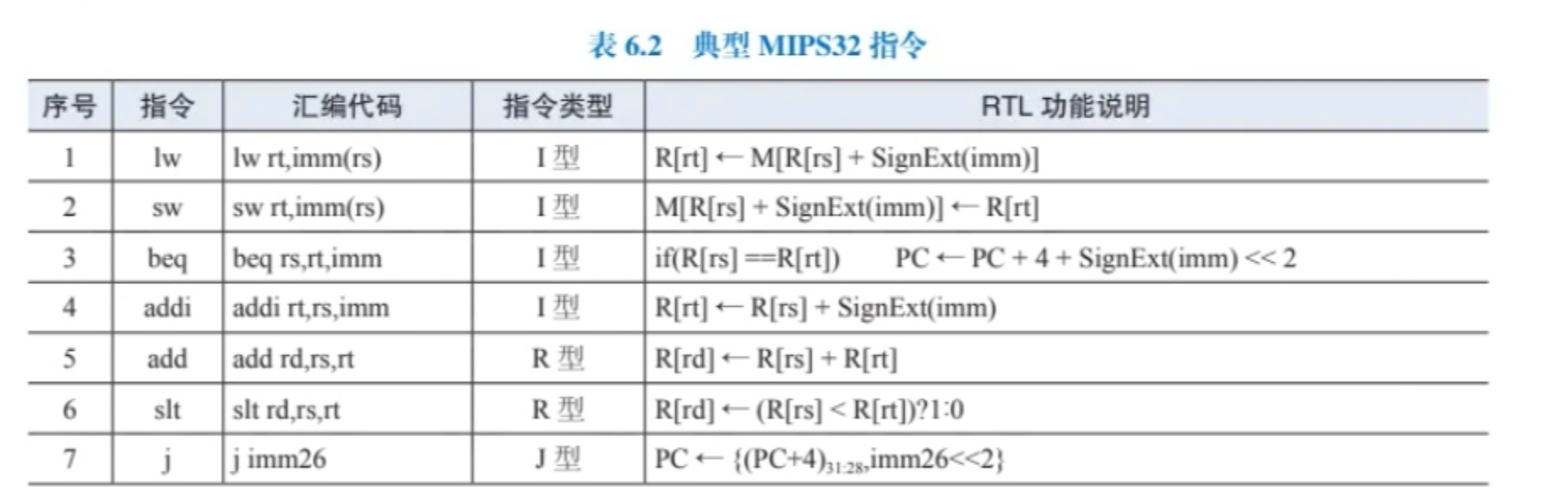
R型指令格式:opcode | rs | rt | rd | shamt | funct
I型指令格式:opcode | rs | rt | immediate
传统三级时序硬布线
机器周期 Mif Mcal Mex 3机器周期*4节拍(T) B : 结果反馈信号 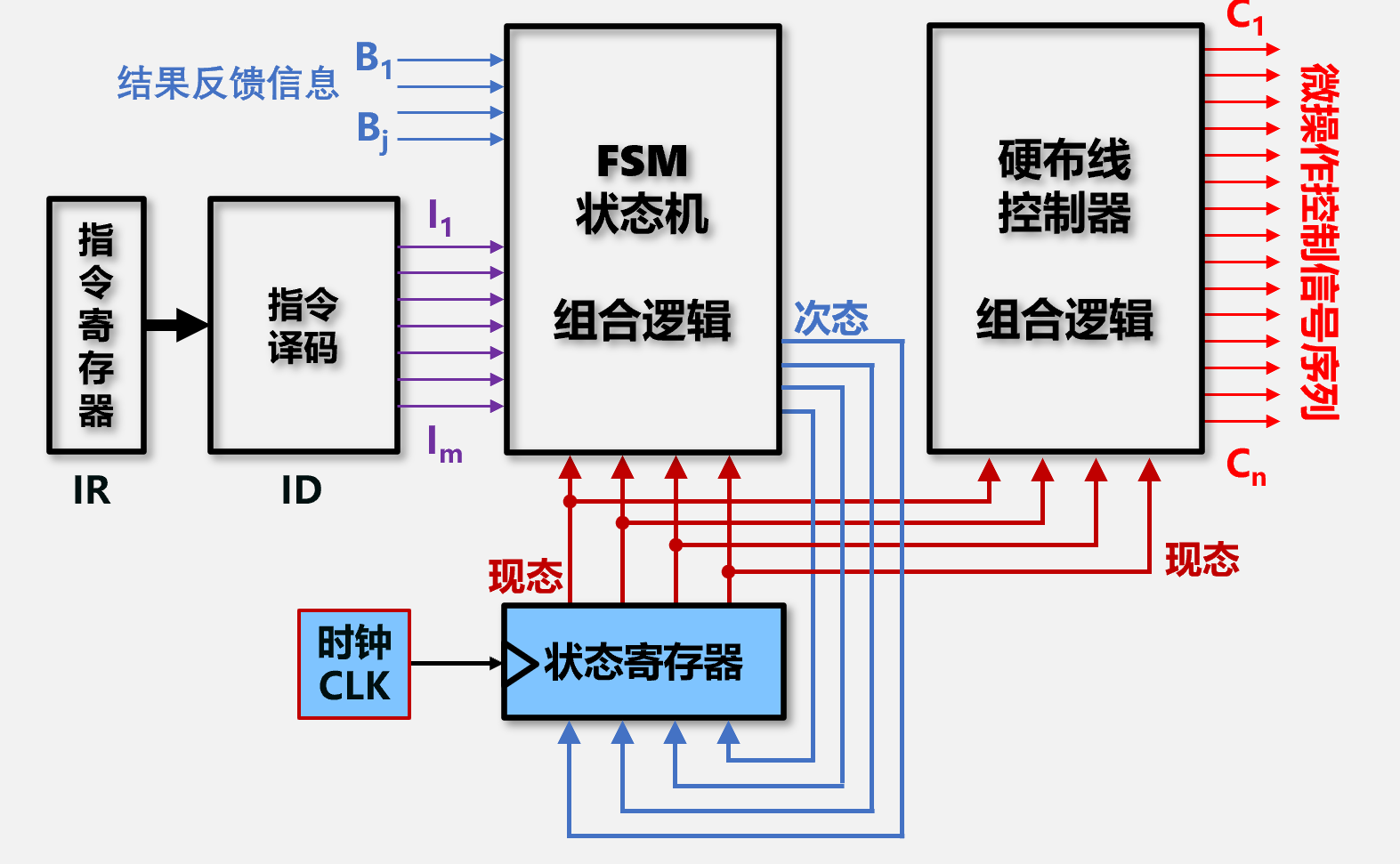
单周期
clk只控制写,在每个指令的数据通路末端,reg,mem,pc
多周期
加了IR,DR,A,B,C
微指令
beq的第二个指令的下址是00000,因为p_eq=1,如果eq=0,转到取值,如果eq=1,p_eq对应的分支地址 P0分支地址通过IR指令字来
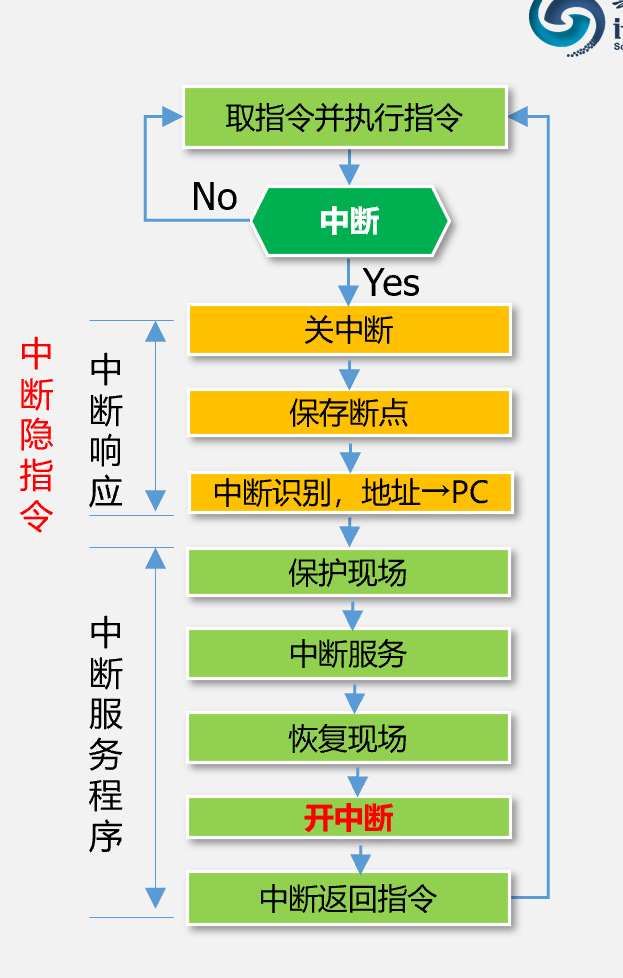
中断
t当多个设备同时发中断请求时,CPU优先响应优先级高中断请求。t当CPU正在处理某个中断请求时,如果有更高优先级的中断请求,则高级中断可以中断正在被服务的低级中断;t同级中断不能中断同级中断;
关中断,保护断点,中断源识别